Try Requests If You Don’t Like Selenium
Recently, I struggled to scrape data from a website built with Vue.js. When I tried to scrape the web data using the traditional Selenium approach, I encountered two problems:
- Captchas appeared when I tried to load more pages.
- Since the site is built with a JavaScript framework, the web page is not static. Accessing information on subpages using Selenium took a lot of time, and the URL did not change, which posed an additional challenge for Selenium.
I’d like to share how I dealt with these issues.
Captcha Solver
Initially, I tried using Chrome extensions to automatically solve captchas while using Selenium to load pages, but they didn’t work well. So, I turned to alternative solutions. I found a Chinese company that provides an excellent service. They offer a Python code snippet that solves captchas with the following process:
- Locate the captcha’s XPath
- Download the captcha image
- Upload the captcha image to their server
- Return the solved captcha value
They charge for this service, and I processed around 21,000 captchas, which cost $3—a fair price. In the next part, I’ll talk about how to integrate it with the Requests package, or with Selenium if you prefer to stick to the traditional method.
The service I used is Chaojiying. It provides a Python function, which can be imported to your python program like this:
!pip install requests
import requests
import chaojiying # Download this part at Chaojiying website
from chaojiying import Chaojiying_Client
def solveCaptcha():
url1 = "URL FOR FETCHING CAPTCHA MODULE"
params1 = {
'type': 'test'
}
response = requests.get(url1, headers=headers, cookies=cookies, params=params1)
data = response.json()
img = data['data']['img']
img_id = data['data']['id']
# Decode and save the captcha image
img_bytes = base64.b64decode(img)
with open('captcha.png', 'wb') as f:
f.write(img_bytes)
with open('captcha.png', 'rb') as f:
im = f.read()
chaojiying = Chaojiying_Client('CHAOJIYING USER NAME', 'CHAOJIYING USER PASSWORD', 'CHAOJIYING ID') # Replace with valid credentials, have to sign up the account first
res = chaojiying.PostPic(im, 1004) # Adjust captcha type ID (1004) if needed
# Submit the solved captcha
url2 = "URL FOR CHECKING CAPTCHA MODULE"
params2 = {
'id': img_id,
'captcha': res["pic_str"],
'type': 'test'
}
# Send the solved captcha
response = requests.get(url2, headers=headers, cookies=cookies, params=params2)
There are many other companies that provide such services, but I haven’t tried them yet. I list them below for your reference:
Try Requests if You Have Trouble Setting Selenium
If you’re having trouble with Selenium, or if you’re tired of dealing with XPaths, you might want to try directly retrieving information from the server database. The way to do this is to use an API.
First, you need to figure out the API format. Right-click on the web page, select “Inspect” in Chrome, and click the Network tab at the top. Now, you can inspect the communication between the front end and the back end.
For example, I use Jekyll Talk. When I click on the link of interest, the Network panel changes.
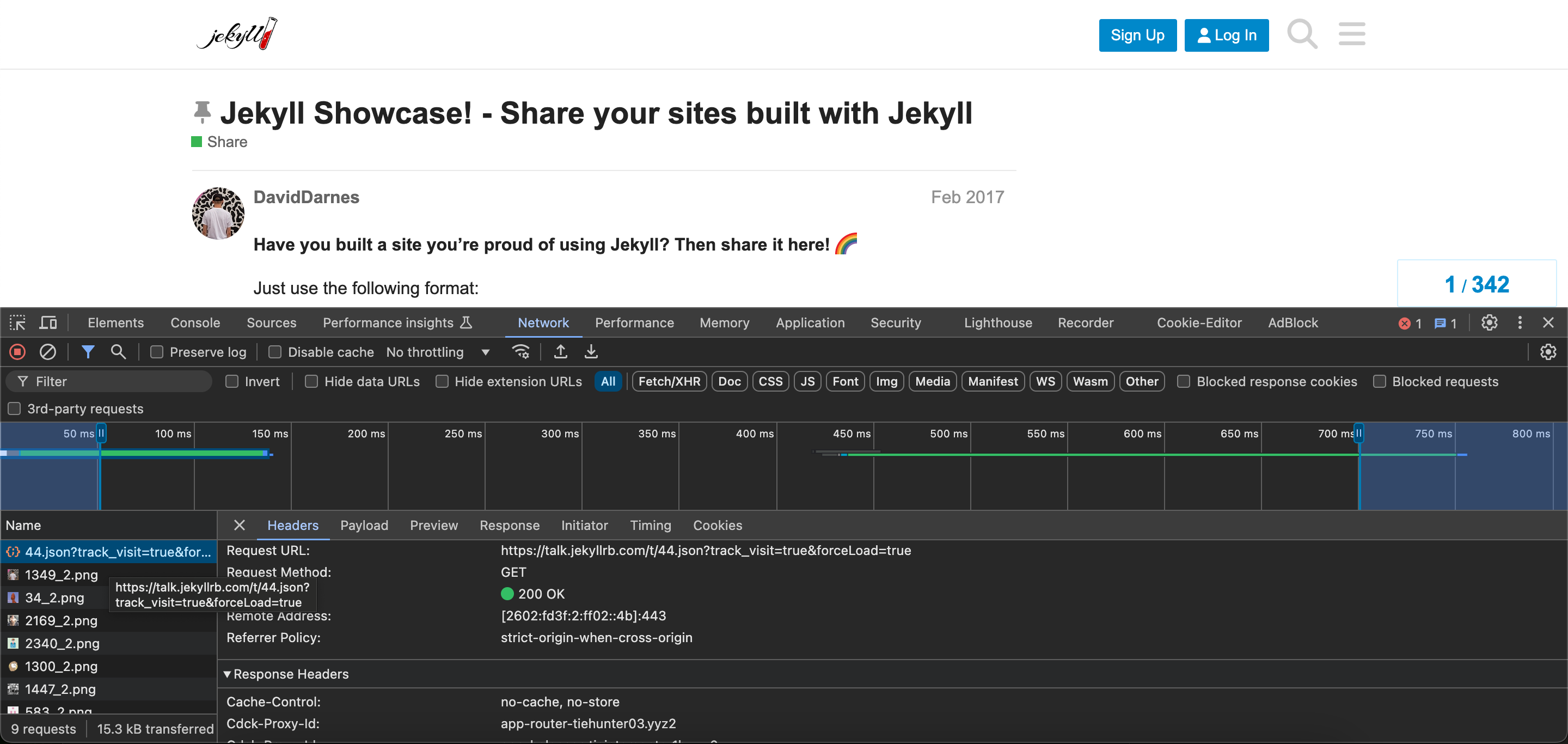
This gives us information about the API request headers and response headers. Therefore, by reconstructing this information ourselves, we can simulate API requests and retrieve responses in JSON format.
Here’s a simple code snippet demonstrating how to use the Requests package in Python to fetch information from the server:
import requests
headers = {INSERT YOUR HEADERS HERE} # You can find your headers in the Inspect panel, or you can fake one
cookies = {INSERT YOUR COOKIES HERE} # You can also find your cookies in the Inspect panel; cookies may change with your login status
url = "" # Insert the API endpoint here
params = {} # Parameters of the website can be seen in 'General -> Request URL'
response = requests.get(url, headers=headers, cookies=cookies, params=params)
print(response.json()) # Get your response in JSON format
Some benefits of doing so:
- Easily get all content directly from the database, which also includes some non-displayed or hard-to-fetch content.
- It’s way faster than Selenium.
- It’s way easier than Selenium.
Captcha Solver + Requests
If we want to combine the two, the logic would be simple:
if Captcha:
get captcha from web server
download captcha
upload captcha to captcha solver server
get captcha key
send captcha key
else:
get content with requests
This article will be continued and refined. Feel free to email me or leave a comment if you have any questions.